Every now and then, someone recommends me to take a look at a flashcard app. It’s often interesting to see what developers have done with design, gamification and UX features, but the content is almost invariably awful. Most recently, I was encouraged to look at Word Pash. The screenshots below are from their promotional video.

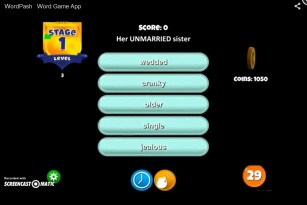


The content problems are immediately apparent: an apparently random selection of target items, an apparently random mix of high and low frequency items, unidiomatic language examples, along with definitions and distractors that are less frequent than the target item. I don’t know if these are representative of the rest of the content. The examples seem to come from ‘Stage 1 Level 3’, whatever that means. (My confidence in the product was also damaged by the fact that the Word Pash website includes one testimonial from a certain ‘Janet Reed – Proud Mom’, whose son ‘was able to increase his score and qualify for academic scholarships at major universities’ after using the app. The picture accompanying ‘Janet Reed’ is a free stock image from Pexels and ‘Janet Reed’ is presumably fictional.)
According to the website, ‘WordPash is a free-to-play mobile app game for everyone in the global audience whether you are a 3rd grader or PhD, wordbuff or a student studying for their SATs, foreign student or international business person, you will become addicted to this fast paced word game’. On the basis of the promotional video, the app couldn’t be less appropriate for English language learners. It seems unlikely that it would help anyone improve their ACT or SAT test scores. The suggestion that the vocabulary development needs of 9-year-olds and doctoral students are comparable is pure chutzpah.
The deliberate study of more or less random words may be entertaining, but it’s unlikely to lead to very much in practical terms. For general purposes, the deliberate learning of the highest frequency words, up to about a frequency ranking of #7500, makes sense, because there’s a reasonably high probability that you’ll come across these items again before you’ve forgotten them. Beyond that frequency level, the value of the acquisition of an additional 1000 words tails off very quickly. Adding 1000 words from frequency ranking #8000 to #9000 is likely to result in an increase in lexical understanding of general purpose texts of about 0.2%. When we get to frequency ranks #19,000 to #20,000, the gain in understanding decreases to 0.01%[1]. In other words, deliberate vocabulary learning needs to be targeted. The data is relatively recent, but the principle goes back to at least the middle of the last century when Michael West argued that a principled approach to vocabulary development should be driven by a comparison of the usefulness of a word and its ‘learning cost’[2]. Three hundred years before that, Comenius had articulated something very similar: ‘in compiling vocabularies, my […] concern was to select the words in most frequent use’[3].
I’ll return to ‘general purposes’ later in this post, but, for now, we should remember that very few language learners actually study a language for general purposes. Globally, the vast majority of English language learners study English in an academic (school) context and their immediate needs are usually exam-specific. For them, general purpose frequency lists are unlikely to be adequate. If they are studying with a coursebook and are going to be tested on the lexical content of that book, they will need to use the wordlist that matches the book. Increasingly, publishers make such lists available and content producers for vocabulary apps like Quizlet and Memrise often use them. Many examinations, both national and international, also have accompanying wordlists. Examples of such lists produced by examination boards include the Cambridge English young learners’ exams (Starters, Movers and Flyers) and Cambridge English Preliminary. Other exams do not have official word lists, but reasonably reliable lists have been produced by third parties. Examples include Cambridge First, IELTS and SAT. There are, in addition, well-researched wordlists for academic English, including the Academic Word List (AWL) and the Academic Vocabulary List (AVL). All of these make sensible starting points for deliberate vocabulary learning.
When we turn to other, out-of-school learners the number of reasons for studying English is huge. Different learners have different lexical needs, and working with a general purpose frequency list may be, at least in part, a waste of time. EFL and ESL learners are likely to have very different needs, as will EFL and ESP learners, as will older and younger learners, learners in different parts of the world, learners who will find themselves in English-speaking countries and those who won’t, etc., etc. For some of these demographics, specialised corpora (from which frequency-based wordlists can be drawn) exist. For most learners, though, the ideal list simply does not exist. Either it will have to be created (requiring a significant amount of time and expertise[4]) or an available best-fit will have to suffice. Paul Nation, in his recent ‘Making and Using Word Lists for Language Learning and Testing’ (John Benjamins, 2016) includes a useful chapter on critiquing wordlists. For anyone interested in better understanding the issues surrounding the development and use of wordlists, three good articles are freely available online. These are:
But, back to ‘general purposes’ …. Frequency lists are the obvious starting point for preparing a wordlist for deliberate learning, but they are very problematic. Frequency rankings depend on the corpus on which they are based and, since these are different, rankings vary from one list to another. Even drawing on just one corpus, rankings can be a little strange. In the British National Corpus, for example, ‘May’ (the month) is about twice as frequent as ‘August’[5], but we would be foolish to infer from this that the learning of ‘May’ should be prioritised over the learning of ‘August’. An even more striking example from the same corpus is the fact that ‘he’ is about twice as frequent as ‘she’[6]: should, therefore, ‘he’ be learnt before ‘she’?
List compilers have to make a number of judgement calls in their work. There is not space here to consider these in detail, but two particularly tricky questions concerning the way that words are chosen may be mentioned: Is a verb like ‘list’, with two different and unrelated meanings, one word or two? Should inflected forms be considered as separate words? The judgements are not usually informed by considerations of learners’ needs. Learners will probably best approach vocabulary development by building their store of word senses: attempting to learn all the meanings and related forms of any given word is unlikely to be either useful or successful.
Frequency lists, in other words, are not statements of scientific ‘fact’: they are interpretative documents. They have been compiled for descriptive purposes, not as ways of structuring vocabulary learning, and it cannot be assumed they will necessarily be appropriate for a purpose for which they were not designed.
A further major problem concerns the corpus on which the frequency list is based. Large databases, such as the British National Corpus or the Corpus of Contemporary American English, are collections of language used by native speakers in certain parts of the world, usually of a restricted social class. As such, they are of relatively little value to learners who will be using English in contexts that are not covered by the corpus. A context where English is a lingua franca is one such example.
A different kind of corpus is the Cambridge Learner Corpus (CLC), a collection of exam scripts produced by candidates in Cambridge exams. This has led to the development of the English Vocabulary Profile (EVP) , where word senses are tagged as corresponding to particular levels in the Common European Framework scale. At first glance, this looks like a good alternative to frequency lists based on native-speaker corpora. But closer consideration reveals many problems. The design of examination tasks inevitably results in the production of language of a very different kind from that produced in other contexts. Many high frequency words simply do not appear in the CLC because it is unlikely that a candidate would use them in an exam. Other items are very frequent in this corpus just because they are likely to be produced in examination tasks. Unsurprisingly, frequency rankings in EVP do not correlate very well with frequency rankings from other corpora. The EVP, then, like other frequency lists, can only serve, at best, as a rough guide for the drawing up of target item vocabulary lists in general purpose apps or coursebooks[7].
There is no easy solution to the problems involved in devising suitable lexical content for the ‘global audience’. Tagging words to levels (i.e. grouping them into frequency bands) will always be problematic, unless very specific user groups are identified. Writers, like myself, of general purpose English language teaching materials are justifiably irritated by some publishers’ insistence on allocating words to levels with numerical values. The policy, taken to extremes (as is increasingly the case), has little to recommend it in linguistic terms. But it’s still a whole lot better than the aleatory content of apps like Word Pash.
[1] See Nation, I.S.P. 2013. Learning Vocabulary in Another Language 2nd edition. (Cambridge: Cambridge University Press) p. 21 for statistical tables. See also Nation, P. & R. Waring 1997. ‘Vocabulary size, text coverage and word lists’ in Schmitt & McCarthy (eds.) 1997. Vocabulary: Description, Acquisition and Pedagogy. (Cambridge: Cambridge University Press) pp. 6 -19
[2] See Kelly, L.G. 1969. 25 Centuries of Language Teaching. (Rowley, Mass.: Rowley House) p.206 for a discussion of West’s ideas.
[3] Kelly, L.G. 1969. 25 Centuries of Language Teaching. (Rowley, Mass.: Rowley House) p. 184
[4] See Timmis, I. 2015. Corpus Linguistics for ELT (Abingdon: Routledge) for practical advice on doing this.
[5] Nation, I.S.P. 2016. Making and Using Word Lists for Language Learning and Testing. (Amsterdam: John Benjamins) p.58
[6] Taylor, J.R. 2012. The Mental Corpus. (Oxford: Oxford University Press) p.151
[7] For a detailed critique of the limitations of using the CLC as a guide to syllabus design and textbook development, see Swan, M. 2014. ‘A Review of English Profile Studies’ ELTJ 68/1: 89-96
