It’s international ELT conference season again, with TESOL Chicago having just come to a close and IATEFL Brighton soon to start. I decided to take a look at how the subject of personalized learning will be covered at the second of these. Taking the conference programme , I trawled through looking for references to my topic.
 My first question was: how do conference presenters feel about personalised learning? One way of finding out is by looking at the adjectives that are found in close proximity. This is what you get.
My first question was: how do conference presenters feel about personalised learning? One way of finding out is by looking at the adjectives that are found in close proximity. This is what you get.
The overall enthusiasm is even clearer when the contexts are looked at more closely. Here are a few examples:
- inspiring assessment, personalising learning
- personalised training can contribute to professionalism and […] spark ideas for teacher trainers
- a personalised educational experience that ultimately improves learner outcomes
- personalised teacher development: is it achievable?
Particularly striking is the complete absence of anything that suggests that personalized learning might not be a ‘good thing’. The assumption throughout is that personalized learning is desirable and the only question that is asked is how it can be achieved. Unfortunately (and however much we might like to believe that it is a ‘good thing’), there is a serious lack of research evidence which demonstrates that this is the case. I have written about this here and here and here . For a useful summary of the current situation, see Benjamin Riley’s article where he writes that ‘it seems wise to ask what evidence we presently have that personalized learning works. Answer: Virtually none. One remarkable aspect of the personalized-learning craze is how quickly the concept has spread despite the almost total absence of rigorous research in support of it, at least thus far.’
Given that personalized learning can mean so many things and given the fact that people do not have space to define their terms in their conference abstracts, it is interesting to see what other aspects of language learning / teaching it is associated with. The four main areas are as follows (in alphabetical order):
- assessment (especially formative assessment) / learning outcomes
- continuous professional development
- learner autonomy
- technology / blended learning
The IATEFL TD SIG would appear to be one of the main promoters of personalized learning (or personalized teacher development) with a one-day pre-conference event entitled ‘Personalised teacher development – is it achievable?’ and a ‘showcase’ forum entitled ‘Forum on Effective & personalised: the holy grail of CPD’. Amusingly (but coincidentally, I suppose), the forum takes place in the ‘Cambridge room’ (see below).
I can understand why the SIG organisers may have chosen this focus. It’s something of a hot topic, and getting hotter. For example:
- Cambridge University Press has identified personalization as one of the ‘six key principles of effective teacher development programmes’ and is offering tailor-made teacher development programmes for institutions.
- NILE and Macmillan recently launched a partnership whose brief is to ‘curate personalised professional development with an appropriate mix of ‘formal’ and ‘informal’ learning delivered online, blended and face to face’.
- Pearson has developed the Pearson’s Teacher Development Interactive (TDI) – ‘an interactive online course to train and certify teachers to deliver effective instruction in English as a foreign language […] You can complete each module on your own time, at your own pace from anywhere you have access to the internet.’
These examples do not, of course, provide any explanation for why personalized learning is a hot topic, but the answer to that is simple. Money. Billions and billions, and if you want a breakdown, have a look at the appendix of Monica Bulger’s report, ‘Personalized Learning: The Conversations We’re Not Having’ . Starting with Microsoft and the Gates Foundation plus Facebook and the Chan / Zuckerberg Foundation, dozens of venture philanthropists have thrown unimaginable sums of money at the idea of personalized learning. They have backed up their cash with powerful lobbying and their message has got through. Consent has been successfully manufactured.
 One of the most significant players in this field is Pearson, who have long been one of the most visible promoters of personalized learning (see the screen capture). At IATEFL, two of the ten conference abstracts which include the word ‘personalized’ are directly sponsored by Pearson. Pearson actually have ten presentations they have directly sponsored or are very closely associated with. Many of these do not refer to personalized learning in the abstract, but would presumably do so in the presentations themselves. There is, for example, a report on a professional development programme in Brazil using TDI (see above). There are two talks about the GSE, described as a tool ‘used to provide a personalised view of students’ language’. The marketing intent is clear: Pearson is to be associated with personalized learning (which is, in turn, associated with a variety of tech tools) – they even have a VP of data analytics, data science and personalized learning.
One of the most significant players in this field is Pearson, who have long been one of the most visible promoters of personalized learning (see the screen capture). At IATEFL, two of the ten conference abstracts which include the word ‘personalized’ are directly sponsored by Pearson. Pearson actually have ten presentations they have directly sponsored or are very closely associated with. Many of these do not refer to personalized learning in the abstract, but would presumably do so in the presentations themselves. There is, for example, a report on a professional development programme in Brazil using TDI (see above). There are two talks about the GSE, described as a tool ‘used to provide a personalised view of students’ language’. The marketing intent is clear: Pearson is to be associated with personalized learning (which is, in turn, associated with a variety of tech tools) – they even have a VP of data analytics, data science and personalized learning.
But the direct funding of the message is probably less important these days than the reinforcement, by those with no vested interests, of the set of beliefs, the ideology, which underpin the selling of personalized learning products. According to this script, personalized learning can promote creativity, empowerment, inclusiveness and preparedness for the real world of work. It sets itself up in opposition to lockstep and factory models of education, and sets learners free as consumers in a world of educational choice. It is a message with which it is hard for many of us to disagree.
 It is also a marvellous example of propaganda, of the way that consent is manufactured. (If you haven’t read it yet, it’s probably time to read Herman and Chomsky’s ‘Manufacturing Consent: The Political Economy of the Mass Media’.) An excellent account of the way that consent for personalized learning has been manufactured can be found at Benjamin Doxtdator’s blog .
It is also a marvellous example of propaganda, of the way that consent is manufactured. (If you haven’t read it yet, it’s probably time to read Herman and Chomsky’s ‘Manufacturing Consent: The Political Economy of the Mass Media’.) An excellent account of the way that consent for personalized learning has been manufactured can be found at Benjamin Doxtdator’s blog .
So, a hot topic it is, and its multiple inclusion in the conference programme will no doubt be welcomed by those who are selling ‘personalized’ products. It must be very satisfying to see how normalised the term has become, how it’s no longer necessary to spend too much on promoting the idea, how it’s so associated with technology, (formative) assessment, autonomy and teacher development … since others are doing it for you.
 Many simple vocabulary learning tasks are relatively simple to generate automatically. These include matching tasks of various kinds, such as the matching of words or phrases to meanings (either in English or the L1), pictures or collocations, as in many flashcard apps. Doing it well is rather harder: the definitions or translations have to be good and appropriate for learners of the level, the pictures need to be appropriate. If, as is often the case, the lexical items have come from a text or form part of a group of some kind, sense disambiguation software will be needed to ensure that the right meaning is being practised. Anyone who has used flashcard apps knows that the major problem is usually the quality of the content (whether it has been automatically generated or written by someone).
Many simple vocabulary learning tasks are relatively simple to generate automatically. These include matching tasks of various kinds, such as the matching of words or phrases to meanings (either in English or the L1), pictures or collocations, as in many flashcard apps. Doing it well is rather harder: the definitions or translations have to be good and appropriate for learners of the level, the pictures need to be appropriate. If, as is often the case, the lexical items have come from a text or form part of a group of some kind, sense disambiguation software will be needed to ensure that the right meaning is being practised. Anyone who has used flashcard apps knows that the major problem is usually the quality of the content (whether it has been automatically generated or written by someone).

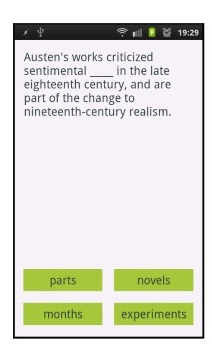 There are a number of applications that offer the possibility of generating cloze tasks from texts selected by the user (learner or teacher). These have not always been designed with the language learner in mind but one that was is the Android app, WordGap (Knoop & Wilske, 2013). Described by its developers as a tool that ‘provides highly individualized exercises to support contextualized mobile vocabulary learning …. It matches the interests of the learner and increases the motivation to learn’. It may well do all that, but then again, perhaps not. As Knoop & Wilske acknowledge, it is only appropriate for adult, advanced learners and its value as a learning task is questionable. The target item that has been automatically selected is ‘novel’, a word that features in the list Oxford 2000 Keywords (as do all three distractors), and therefore ought to be well below the level of the users. Some people might find this fun, but, in terms of learning, they would probably be better off using an app that made instant look-up of words in the text possible.
There are a number of applications that offer the possibility of generating cloze tasks from texts selected by the user (learner or teacher). These have not always been designed with the language learner in mind but one that was is the Android app, WordGap (Knoop & Wilske, 2013). Described by its developers as a tool that ‘provides highly individualized exercises to support contextualized mobile vocabulary learning …. It matches the interests of the learner and increases the motivation to learn’. It may well do all that, but then again, perhaps not. As Knoop & Wilske acknowledge, it is only appropriate for adult, advanced learners and its value as a learning task is questionable. The target item that has been automatically selected is ‘novel’, a word that features in the list Oxford 2000 Keywords (as do all three distractors), and therefore ought to be well below the level of the users. Some people might find this fun, but, in terms of learning, they would probably be better off using an app that made instant look-up of words in the text possible.