When the internet arrived on our desktops in the 1990s, language teachers found themselves able to access huge amounts of authentic texts of all kinds. It was a true game-changer. But when it came to ELT dedicated websites, the pickings were much slimmer. There was a very small number of good ELT resource sites (onestopenglish stood out from the crowd), but more ubiquitous and more enduring were the sites offering downloadable material shared by teachers. One of these, ESLprintables.com, currently has 1,082,522 registered users, compared to the 700,000+ of onestopenglish.
The resources on offer at sites such as these range from texts and scripted dialogues, along with accompanying comprehension questions, to grammar explanations and gapfills, vocabulary matching tasks and gapfills, to lists of prompts for discussions. Almost all of it is unremittingly awful, a terrible waste of the internet’s potential.
Ten years later, interactive online possibilities began to appear. Before long, language teachers found themselves able to use things like blogs, wikis and Google Docs. It was another true game changer. But when it came to ELT dedicated things, the pickings were much slimmer. There is some useful stuff (flashcard apps, for example) out there, but more ubiquitous are interactive versions of the downloadable dross that already existed. Learning platforms, which have such rich possibilities, are mostly loaded with gapfills, drag-and-drop, multiple choice, and so on. Again, it seems such a terrible waste of the technology’s potential. And all of this runs counter to what we know about how people learn another language. It’s as if decades of research into second language acquisition had never taken place.
And now we have AI and large language models like GPT. The possibilities are rich and quite a few people, like Sam Gravell and Svetlana Kandybovich, have already started suggesting interesting and creative ways of using the technology for language teaching. Sadly, though, technology has a tendency to bring out the worst in approaches to language teaching, since there’s always a bandwagon to be jumped on. Welcome to Twee, A.I. powered tools for English teachers, where you can generate your own dross in a matter of seconds. You can generate texts and dialogues, pitched at one of three levels, with or without target vocabulary, and produce comprehension questions (open questions, T / F, or M / C), exercises where vocabulary has to be matched to definitions, word-formation exercises, gapfills. The name of the site has been carefully chosen (Cambridge dictionary defines ‘twee’ as ‘artificially attractive’).
I decided to give it a try. Twee uses the same technology as ChatGPT and the results were unsurprising. I won’t comment in any detail on the intrinsic interest or the accuracy of factual information in the texts. They are what you might expect if you have experimented with ChatGPT. For the same reason, I won’t go into details about the credibility or naturalness of the dialogues. Similarly, the ability of Twee to gauge the appropriacy of texts for particular levels is poor: it hasn’t been trained on a tagged learner corpus. In any case, having only three level bands (A1/A2, B1/B2 and C1/C2) means that levelling is far too approximate. Suffice to say that the comprehension questions, vocabulary-item selection, vocabulary practice activities would all require very heavy editing.
Twee is still in beta, and, no doubt, improvements will come as the large language models on which it draws get bigger and better. Bilingual functionality is a necessary addition, and is doable. More reliable level-matching would be nice, but it’s a huge technological challenge, besides being theoretically problematic. But bigger problems remain and these have nothing to do with technology. Take a look at the examples below of how Twee suggests its reading comprehension tasks (open questions, M / C, T / F) could be used with some Beatles songs.
Is there any point getting learners to look at a ‘dialogue’ (on the topic of yellow submarines) like the one below? Is there any point getting learners to write essays using prompts such as those below?
What possible learning value could tasks such as these have? Is there any credible theory of language learning behind any of this, or is it just stuff that would while away some classroom time? AI meets ESLprintables – what a waste of the technology’s potential!
Edtech vendors like to describe their products as ‘solutions’, but the educational challenges, which these products are supposedly solutions to, often remain unexamined. Poor use of technology can exacerbate these challenges by making inappropriate learning materials more easily available.
You could be forgiven for wondering what, precisely, digital literacies are. In the first edition of ‘Digital Literacies’, Dudeney et al. (2013:2) define the term as ‘the individual and social skills needed to effectively interpret, manage, share and create meaning in the growing range of digital communication channels’. This is pretty broad, and would seem to encompass more or less anything that people do with digital technology, including the advanced arts of trolling and scamming. Nine years later, in the new edition of this book (Pegrum et al., 2022:5), the authors modify their definition a little: ‘the individual and social skills needed to effectively manage meaning in an era of digitally networked, often blended, communication’. This is broader still. In the intervening years there has been a massive proliferation of ways of describing specific digital literacies, as well as more frameworks of digital literacies than anyone (bar people writing about the topic) could possibly want. Of course, there is much in common between all these descriptive and taxonomic efforts, but there is also much that differs. What, precisely, ‘digital literacies’ means changes over both time and space. It carries different meanings in Australia, Sweden and Argentina, and, perhaps, it only makes sense to have a local conceptualisation of the term (Pangrazio et al., 2020). By the time you have figured out what these differences are, things will have moved on. Being ‘digitally-literate’ literate is an ongoing task.
What, precisely, ‘digital literacies’ are only really matters when we are told that it is vital to teach them. It’s easy to agree that digital skills are quite handy in this networked world, but, unless we have a very clear idea of what they are, it’s not going to be easy to know which ones to teach or how to teach them. Before we get caught up in the practical pedagogical details, it might be useful to address three big questions:
How useful it is to talk about digital literacies?
Can digital literacies be taught?
Should digital literacies be taught as part of the English language curriculum?
How useful is it to talk about digital literacies?
Let’s take one example of a framework: the Cambridge Life Competencies Framework (CLC). The CLC lists six key competencies (creative thinking, critical thinking, communication, collaboration, learning to learn, and social responsibilities). Underpinning and informing these six competencies are three ‘foundation layers’: ‘emotional development’, ‘discipline knowledge’ and ‘digital literacy’. Digital literacy is broken down as follows:
It’s a curious amalgam of relatively straightforward skills and much more complex combinations of skills with knowledge, attitudes and dispositions. In the former category (see the first box in the chart above), we would find things like the ability to use tags, hashtags, search engines, and filters. In the latter (see the second box in the chart above), we would find things like the ability to recognise fake news or to understand how and why personally targeted advertising is such a money-spinner.
Another example, this one, from Pegrum et al (2018), is more complex and significantly more detailed. On the more technical side, we see references to the ability to navigate within multimodal gaming, VR and AR environments, or the ability to write and modify computer code. And for more complex combinations of skills, knowledge, attitudes and dispositions, we have things like the ability to develop a reputation and exert influence within online networks, or ‘the ability to exert a positive influence (online) by adopting a stance of intellectual humility and ethical pluralism’.
This is all a far remove from only seven years ago when ‘digital literacies’ were described as ‘the practices of reading, writing and communication made possible by digital media’ (Hafner et al., 2015) and the kinds of skills required were almost all closely connected to reading and writing. The digital world has changed, and so has our understanding of what it means to operate effectively within that world. Perhaps it is time, too, to change our terminology: ‘literacies’ is still with us, but it seems almost wilfully misleading. ‘Abilities’ or ‘competencies’ would seem to be much more appropriate terms to refer to what we are discussing in these frameworks, but ‘abilities’ probably isn’t sciency enough, and ‘competencies’ has already been done to death.
The problem with lumping all these things together under a single superordinate is that it seems to imply that there is some sort of equivalence between all the subordinate labels, that there is some categorial similarity. Pegrum et al (2022) acknowledge that there are differences of complexity between these ‘literacies’ – they use a star system to indicate degree of complexity. But I think that there is no sufficiently strong reason to put some of these things together in the first place. Dudeney at al (2013: 14) note that some of their literacies are ‘macroliteracies’ – ‘in other words, a literacy which draws on numerous other literacies – and involves linguistic, multimedia, spatial, kinaesthetic and other skills’. Why, then, call them ‘literacies’ at all? The only connection between knowing how to generate a LOLcat post and knowing how to ‘remain non-judgemental towards new perspectives, multiple viewpoints, and shifting contexts’ is that both are related to our use of digital technology. But since there is very little in our lives that is not now related in some way to digital technology, is this good enough reason to bracket these two abilities together?
Pegrum et al (2022) found that they needed to expand their list of digital literacies in the new edition of their book, and they will no doubt need to do so again nine years from now. But is the fact that something could be included in a taxonomy a good reason for actually including it? ‘Code literacy’, for example, seems rather less urgent now than it did nine years ago. I have never been convinced by gaming literacy or remix literacy. Are these really worth listing alongside the others in the table? Even if they are, nobody (including Pegrum et al.) would disagree that some prioritisation is necessary. However, when we refer to ‘digital literacies’ and how vital it is to teach them, we typically don’t specify a particular literacy and not another. We risk committing the logical error of assuming that something that holds true for a group or category, also holds true for all the members of the group or subordinates of the category.
Can digital literacies be taught?
There is clearly no particular problem in teaching and learning some digital literacies, especially the more technical ones. Unfortunately, the more specific and technical we are (e.g. when we mention a particular digital tool), the more likely it is that its shelf-life will be limited. Hardware comes and goes (I haven’t had to format a floppy disc for a while), as do apps and software. To the risk of wasting time teaching a skill that may soon be worthless, we may add the risk of not including literacies that have not yet found their way into the taxonomies. Examples include knowing how to avoid plagiarism detectors (as opposed to avoiding plagiarism) or how to use GPT-3 (and soon GPT-4) text generators. Handy for students.
The choice of digital tools is crucial when one of the key pieces of advice for teaching digital literacy is to integrate the use of digital tools into lessons (e.g. in the Cambridge Life Competencies Digital Literacy booklet). This advice skates over the key questions of which tool, and which literacy is being targeted (and why). Watching TikTok videos, using Mentimeter in class, or having a go with a VR headset may serve various educational purposes, but it would be stretching a point to argue that these activities will do much for anyone’s digital literacy. Encouraging teachers to integrate technology into their lessons (government policy in some countries) makes absolutely no sense unless the desired outcome – digital literacy – is precisely defined in advance. It rarely is. See here for further discussion.
Encouragement to include technology, any old technology, in lessons is almost never grounded in claims that a particular technical skill (e.g. navigating TikTok) has any pressing value. Rather, the justification usually comes from reference to what might be called ‘higher-order’ skills, like critical thinking: what I referred to earlier as curious amalgams of relatively straightforward skills and much more complex combinations of skills with knowledge, attitudes and dispositions.
The problem here is that it remains very uncertain whether things like ethical literacy or critical digital literacy are likely to be learnt through instruction. They can certainly be practised, and Pegrum et al (2022) have some very nice activities. The aims of these activities is typically described using a vague ‘raise awareness of’ formula, but whether they will lead, for example, to any improved ability ‘to exert a positive influence (online) by adopting a stance of intellectual humility and ethical pluralism’ is debatable. Much as the world might be a better place if classroom activities of this kind did actually work, research evidence is sadly lacking. For a more detailed look at the problems of trying to teach critical digital literacy / media information literacy, see here.
Should digital literacies be part of the English language curriculum?
So, is it ‘crucial for language teaching to […] encompass the digital literacies which are increasingly central to learners’ […] lives’ (Pegrum et al, 2022)? Well, it all depends on which digital literacies we are talking about. It also depends on what kind of learners in what kinds of learning contexts. And it depends on both institutional objectives and the personal objectives of the learners themselves. So, ‘crucial’, no, but we’ll put the choice of adjective down to rhetorical flourish.
Is it true that ‘digital literacies are as important to language learning as […] reading and writing skills […]’ (Pegrum et al., 2022: 1)? Clearly not. Since it’s hard to imagine any kind of digital literacy without some reading skills preceding it, the claim that they are comparable in importance is also best understood as rhetorical flourish.
A modicum of critical (digital) literacy is helpful when it comes to reading literature on digital literacies.
References
Dudeney, G., Hockly, N. & Pegrum, M. (2013) Digital Literacies. Harlow: Pearson Education
Hafner, C.A., Chik, A. & Jones, R. H. (2015) Digital Literacies and Language Learning, Language Learning & Technology, 19 (3): 1- 7
Pangrazio, L., Godhe, A.-L., & Ledesma, A. G. L. (2020) What is digital literacy? A comparative review of publications across three language contexts. E-Learning and Digital Media, 17(6), 442–459. https://doi.org/10.1177/204275302094629
Pegrum, M., Hockly, N. & Dudeney, G. (2022) Digital Literacies 2nd Edition. New York: Routledge
Pegrum, M., Dudeney, G. & Hockly, N. (2018) Digital Literacies Revisited. The European Journal of Applied Linguistics and TEFL, 7 (2): 3 – 24
There’s an aspect of language learning which everyone agrees is terribly important, but no one can quite agree on what to call it. I’m talking about combinations of words, including fixed expressions, collocations, phrasal verbs and idioms. These combinations are relatively fixed, cannot always be predicted from their elements or generated by grammar rules (Laufer, 2022). They are sometimes referred to as formulaic sequences, formulaic expressions, lexical bundles or lexical chunks, among other multiword items. They matter to English language learners because a large part of English consists of such combinations. Hill (2001) suggests this may be up to 70%. More conservative estimates report 58.6% of writing and 52.3% of speech (Erman & Warren, 2000). Some of these combinations (e.g. ‘of course’, ‘at least’) are so common that they fall into lists of the 1000 most frequent lexical items in the language.
By virtue of their ubiquity and frequency, they are important both for comprehension of reading and listening texts and for the speed at which texts can be processed. This is because knowledge of these combinations ‘makes discourse relatively predictable’ (Boers, 2020). Similarly, such knowledge can significantly contribute to spoken fluency because combinations ‘can be retrieved from memory as prefabricated units rather than being assembled at the time of speaking’ (Boer, 2020).
So far, so good, but from here on, the waters get a little muddier. Given their importance, what is the best way for a learner to acquire a decent stock of them? Are they best acquired through incidental learning (through meaning-focused reading and listening) or deliberate learning (e.g. with focused exercises of flashcards)? If the former, how on earth can we help learners to make sure that they get exposure to enough combinations enough times? If the latter, what kind of practice works best and, most importantly, which combinations should be selected? With, at the very least, many tens of thousands of such combinations, life is too short to learn them all in a deliberate fashion. Some sort of triage is necessary, but how should we go about this? Frequency of occurrence would be one obvious criterion, but this merely raises the question of what kind of database should be used to calculate frequency – the spoken discourse of children will reveal very different patterns from the written discourse of, say, applied linguists. On top of that, we cannot avoid consideration of the learners’ reasons for learning the language. If, as is statistically most probable, they are learning English to use as a lingua franca, how important or relevant is it to learn combinations that are frequent, idiomatic and comprehensible in native-speaker cultures, but may be rare and opaque in many English as a Lingua Franca contexts?
There are few, if any, answers to these big questions. Research (e.g. Pellicer-Sánchez, 2020) can give us pointers, but, the bottom line is that we are left with a series of semi-informed options (see O’Keeffe et al., 2007: 58 – 99). So, when an approach comes along that claims to use software to facilitate the learning of English formulaic expressions (Lin, 2022) I am intrigued, to say the least.
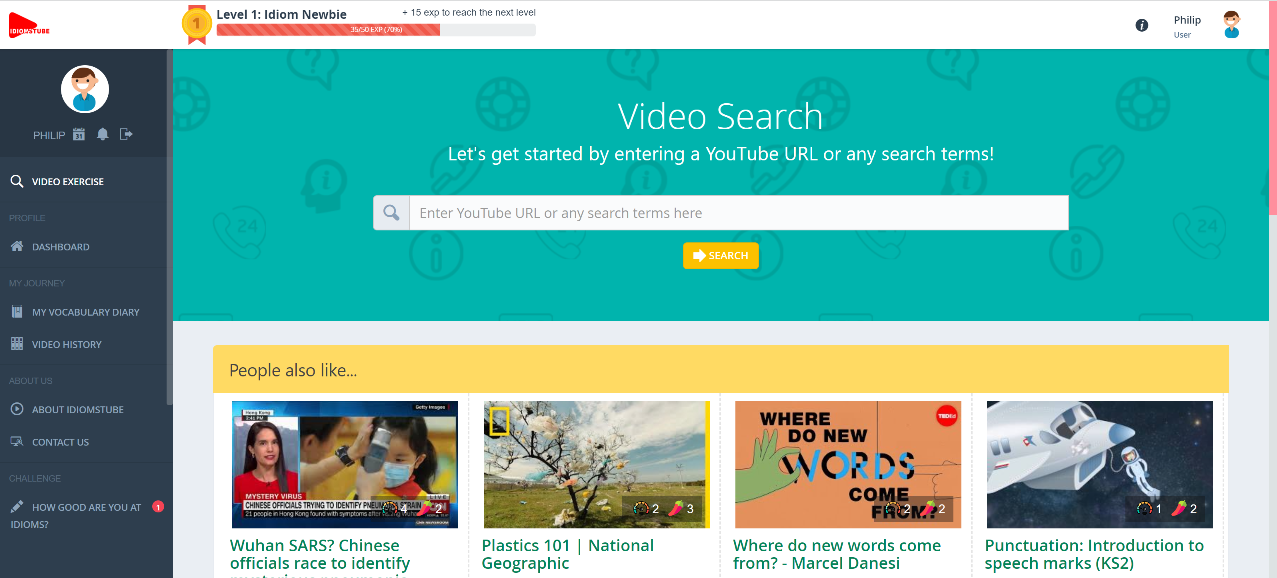
The program is, slightly misleadingly, called IdiomsTube (https://www.idiomstube.com). A more appropriate title would have been IdiomaticityTube (as it focuses on ‘speech formulae, proverbs, sayings, similes, binomials, collocations, and so on’), but I guess ‘idioms’ is a more idiomatic word than ‘idiomaticity’. IdiomsTube allows learners to choose any English-captioned video from YouTube, which is then automatically analysed to identify from two to six formulaic expressions that are presented to the learner as learning objects. Learners are shown these items; the items are hyperlinked to (good) dictionary entries; learners watch the video and are then presented with a small variety of practice tasks. The system recommends particular videos, based on an automated analysis of their difficulty (speech rate and a frequency count of the lexical items they include) and on recommendations from previous users. The system is gamified and, for class use, teachers can track learner progress.
When an article by the program’s developer, Phoebe Lin, (in my view, more of an advertising piece than an academic one) came out in the ReCALL journal, she tweeted that she’d love feedback. I reached out but didn’t hear back. My response here is partly an evaluation of Dr Lin’s program, partly a reflection on how far technology can go in solving some of the knotty problems of language learning.
Incidental and deliberate learning
Researchers have long been interested in looking for ways of making incidental learning of lexical items more likely to happen (Boers, 2021: 39 ff.), of making it more likely that learners will notice lexical items while focusing on the content of a text. Most obviously, texts can be selected, written or modified so they contain multiple instances of a particular item (‘input flooding’). Alternatively, texts can be typographically enhanced so that particular items are highlighted in some way. But these approaches are not possible when learners are given the freedom to select any video from YouTube and when the written presentations are in the form of YouTube captions. Instead, IdiomsTube presents the items before the learner watches the video. They are, in effect, told to watch out for these items in advance. They are also given practice tasks after viewing.
The distinction between incidental and deliberate vocabulary learning is not always crystal-clear. In this case, it seems fairly clear that the approach is more slanted to deliberate learning, even though the selection of video by the learner is determined by a focus on content. Whether this works or not will depend on (1) the level-appropriacy of the videos that the learner watches, (2) the effectiveness of the program in recommending / identifying appropriate videos, (3) the ability of the program to identify appropriate formulaic expressions as learning targets in each video, and (4) the ability of the program to generate appropriate practice of these items.
Evaluating the level of YouTube videos
What makes a video easy or hard to understand? IdiomsTube attempts this analytical task by calculating (1) the speed of the speech and (2) the difficulty of the lexis as determined by the corpus frequency of these items. This gives a score out of five for each category (speed and difficulty). I looked at fifteen videos, all of which were recommended by the program. Most of the ones I looked at were scored at Speed #3 and Difficulty #1. One that I looked at, ‘Bruno Mars Carpool Karaoke’, had a speed of #2 and a difficulty of #1 (i.e. one of the easiest). The video is 15 minutes long. Here’s an extract from the first 90 seconds:
Let’s set this party off right, put yo’ pinky rings up to the moon, twenty four karat magic in the air, head to toe soul player, second verse for the hustlas, gangstas, bad bitches and ya ugly ass friends, I gotta show how a pimp get it in, and they waking up the rocket why you mad
Whoa! Without going into details, it’s clear that something has gone seriously wrong. Evaluating the difficulty of language, especially spoken language, is extremely complex (not least because there’s no objective measure of such a thing). It’s not completely dissimilar to the challenge of evaluating the accuracy, appropriacy and level of sophistication of a learner’s spoken language, and we’re a long way from being able to do that with any acceptable level of reliability. At least, we’re a long, long way from being able to do it well when there are no constraints on the kind of text (which is the case when taking the whole of YouTube as a potential source). Especially if we significantly restrict topic and text type, we can train software to do a much better job. However, this will require human input: it cannot be automated without.
The length of these 15 videos ranged from 3.02 to 29.27 minutes, with the mean length being about 10 minutes, and the median 8.32 minutes. Too damn long.
Selecting appropriate learning items
The automatic identification of formulaic language in a text presents many challenges: it is, as O’Keeffe et al. (2007: 82) note, only partially possible. A starting point is usually a list, and IdiomsTube begins with a list of 53,635 items compiled by the developer (Lin, 2022) over a number of years. The software has to match word combinations in the text to items in the list, and has to recognise variant forms. Formulaic language cannot always be identified just by matching to lists of forms: a piece of cake may just be a piece of cake, and therefore not a piece of cake to analyse. 53,365 items may sound like a lot, but a common estimate of the number of idioms in English is 25,000. The number of multiword units is much, much higher. 53,365 is not going to be enough for any reliable capture.
Since any given text is likely to contain a lot of formulaic language, the next task is to decide how to select for presentation (i.e. as learning objects) from those identified. The challenge is, as Lin (2022) remarks, both technical and theoretical: how can frequency and learnability be measured? There are no easy answers, and the approach of IdiomsTube is, by its own admission, crude. The algorithm prioritises longer items that contain lower frequency single items, and which have a low frequency of occurrence in a corpus of 40,000 randomly-sampled YouTube videos. The aim is to focus on formulaic language that is ‘more challenging in terms of composition (i.e. longer and made up of more difficult words) and, therefore, may be easier to miss due to their infrequent appearance on YouTube’. My immediate reaction is to question whether this approach will not prioritise items that are not worth the bother of deliberate learning in the first place.
The proof is in the proverbial pudding, so I looked at the learning items that were offered by my sample of 15 recommended videos. Sadly, IdiomsTube does not even begin to cut the mustard. The rest of this section details why the selection was so unsatisfactory: you may want to skip this and rejoin me at the start of the next section.
In total 85 target items were suggested. Of these 39 (just under half) were not fixed expressions. They were single items. Some of these single items (e.g. ‘blog’ and ‘password’ would be extremely easy for most learners). Of the others, 5 were opaque idioms (the most prototypical kind of idiom), the rest were collocations and fixed (but transparent) phrases and frames.
Some items (e.g. ‘I rest my case’) are limited in terms of the contexts in which they can be appropriately used.
Some items did not appear to be idiomatic in any way. ‘We need to talk’ and ‘able to do it’, for example, are strange selections, compared to others in their respective lists. They are also very ‘easy’: if you don’t readily understand items like these, you wouldn’t have a hope in hell of understanding the video.
There were a number of errors in the recommended target items. Errors included duplication of items within one set (‘get in the way’ + ‘get in the way of something’), misreading of an item (‘the shortest’ misread as ‘the shorts’), mislabelling of an item (‘vend’ instead of ‘vending machine’), linking to the wrong dictionary entry (e.g. ‘mini’ links to ‘miniskirt’, although in the video ‘mini’ = ‘small’, or, in another video, ‘stoke’ links to ‘stoked’, which is rather different!).
The selection of fixed expressions is sometimes very odd. In one video, the following items have been selected: get into an argument, vend, from the ground up, shovel, we need to talk, prefecture. The video contains others which would seem to be better candidates, including ‘You can’t tell’ (which appears twice), ‘in charge of’, ‘way too’ (which also appears twice), and ‘by the way’. It would seem, therefore, that some inappropriate items are selected, whilst other more appropriate ones are omitted.
There is a wide variation in the kind of target item. One set, for example, included: in order to do, friction, upcoming, run out of steam, able to do it, notification. Cross-checking with Pearson’s Global Scale of English, we have items ranging from A2 to C2+.
The challenges of automation
IdiomsTube comes unstuck on many levels. It fails to recommend appropriate videos to watch. It fails to suggest appropriate language to learn. It fails to provide appropriate practice. You wouldn’t know this from reading the article by Phoebe Lin in the ReCALL journal which does, however, suggest that ‘further improvements in the design and functions of IdiomsTube are needed’. Necessary they certainly are, but the interesting question is how possible they are.
My interest in IdiomsTube comes from my own experience in an app project which attempted to do something not completely dissimilar. We wanted to be able to evaluate the idiomaticity of learner-generated language, and this entailed identifying formulaic patterns in a large corpus. We wanted to develop a recommendation engine for learning objects (i.e. the lexical items) by combining measures of frequency and learnability. We wanted to generate tasks to practise collocational patterns, by trawling the corpus for contexts that lent themselves to gapfills. With some of these challenges, we failed. With others, we found a stopgap solution in human curation, writing and editing.
IdiomsTube is interesting, not because of what it tells us about how technology can facilitate language learning. It’s interesting because it tells us about the limits of technological applications to learning, and about the importance of sorting out theoretical challenges before the technical ones. It’s interesting as a case study is how not to go about developing an app: its ‘special enhancement features such as gamification, idiom-of-the-day posts, the IdiomsTube Teacher’s interface and IdiomsTube Facebook and Instagram pages’ are pointless distractions when the key questions have not been resolved. It’s interesting as a case study of something that should not have been published in an academic journal. It’s interesting as a case study of how techno-enthusiasm can blind you to the possibility that some learning challenges do not have solutions that can be automated.
References
Boers, F. (2020) Factors affecting the learning of multiword items. In Webb, S. (Ed.) The Routledge Handbook of Vocabulary Studies. Abingdon: Routledge. pp. 143 – 157
Boers, F. (2021) Evaluating Second Language Vocabulary and Grammar Instruction. Abingdon: Routledge
Erman, B. & Warren, B. (2000) The idiom principle and the open choice principle. Text, 20 (1): pp. 29 – 62
Hill, J. (2001) Revising priorities: from grammatical failure to collocational success. In Lewis, M. (Ed.) Teaching Collocation: further development in the Lexical Approach. Hove: LTP. Pp.47- 69
Laufer, B. (2022) Formulaic sequences and second language learning. In Szudarski, P. & Barclay, S. (Eds.) Vocabulary Theory, Patterning and Teaching. Bristol: Multilingual Matters. pp. 89 – 98
Lin, P. (2022). Developing an intelligent tool for computer-assisted formulaic language learning from YouTube videos. ReCALL 34 (2): pp.185–200.
O’Keeffe, A., McCarthy, M. & Carter, R. (2007) From Corpus to Classroom. Cambridge: Cambridge University Press
Pellicer-Sánchez, A. (2020) Learning single words vs. multiword items. In Webb, S. (Ed.) The Routledge Handbook of Vocabulary Studies. Abingdon: Routledge. pp. 158 – 173
More and more language learning is taking place, fully or partially, on online platforms and the affordances of these platforms for communicative interaction are exciting. Unfortunately, most platform-based language learning experiences are a relentless diet of drag-and-drop, drag-till-you-drop grammar or vocabulary gap-filling. The chat rooms and discussion forums that the platforms incorporate are underused or ignored. Lindsay Clandfield and Jill Hadfield’s new book is intended to promote online interaction between and among learners and the instructor, rather than between learners and software.
Interaction Online is a recipe book, containing about 80 different activities (many more if you consider the suggested variations). Subtitled ‘Creative activities for blended learning’, the authors have selected and designed the activities so that any teacher using any degree of blend (from platform-based instruction to occasional online homework) will be able to use them. The activities do not depend on any particular piece of software, as they are all designed for basic tools like Facebook, Skype and chat rooms. Indeed, almost every single activity could be used, sometimes with some slight modification, for teachers in face-to-face settings.
A recipe book must be judged on the quality of the activities it contains, and the standard here is high. They range from relatively simple, short activities to much longer tasks which will need an hour or more to complete. An example of the former is a sentence-completion activity (‘Don’t you hate / love it when ….?’ – activity 2.5). As an example of the latter, there is a complex problem-solving information-gap where students have to work out the solution to a mystery (activity 6.13), an activity which reminds me of some of the material in Jill Hadfield’s much-loved Communication Games books.
In common with many recipe books, Interaction Online is not an easy book to use, in the sense that it is hard to navigate. The authors have divided up the tasks into five kinds of interaction (personal, factual, creative, critical and fanciful), but it is not always clear precisely why one activity has been assigned to one category rather than another. In any case, the kind of interaction is likely to be less important to many teachers than the kind and amount of language that will be generated (among other considerations), and the table of contents is less than helpful. The index at the back of the book helps to some extent, but a clearer tabulation of activities by interaction type, level, time required, topic and language focus (if any) would be very welcome. Teachers will need to devise their own system of referencing so that they can easily find activities they want to try out.
Again, like many recipe books, Interaction Online is a mix of generic task-types and activities that will only work with the supporting materials that are provided. Teachers will enjoy the latter, but will want to experiment with the former and it is these generic task-types that they are most likely to add to their repertoire. In activity 2.7 (‘Foodies’ – personal interaction), for example, students post pictures of items of food and drink, to which other students must respond with questions. The procedure is clear and effective, but, as the authors note, the pictures could be of practically anything. ‘From pictures to questions’ might be a better title for the activity than ‘Foodies’. Similarly, activity 3.4 (‘Find a festival’ –factual interaction) uses a topic (‘festivals’), rather than a picture, to generate questions and responses. The procedure is slightly different from activity 2.7, but the interactional procedures of the two activities could be swapped around as easily as the topics could be changed.
Perhaps the greatest strength of this book is the variety of interactional procedures that is suggested. The majority of activities contain (1) suggestions for a stimulus, (2) suggestions for managing initial responses to this stimulus, and (3) suggestions for further interaction. As readers work their way through the book, they will be struck by similarities between the activities. The final chapter (chapter 8: ‘Task design’) provides an excellent summary of the possibilities of communicative online interaction, and more experienced teachers may want to read this chapter first.
Chapter 7 provides a useful, but necessarily fairly brief, overview of considerations regarding feedback and assessment
Overall, Interaction Online is a very rich resource, and one that will be best mined in multiple visits. For most readers, I would suggest an initial flick through and a cherry-picking of a small number of activities to try out. For materials writers and course designers, a better starting point may be the final two chapters, followed by a sampling of activities. For everyone, though, Online Interaction is a powerful reminder that technology-assisted language learning could and should be far more than what is usually is.








 More and more language learning is taking place, fully or partially, on online platforms and the affordances of these platforms for communicative interaction are exciting. Unfortunately, most platform-based language learning experiences are a relentless diet of drag-and-drop, drag-till-you-drop grammar or vocabulary gap-filling. The chat rooms and discussion forums that the platforms incorporate are underused or ignored. Lindsay Clandfield and Jill Hadfield’s new book is intended to promote online interaction between and among learners and the instructor, rather than between learners and software.
More and more language learning is taking place, fully or partially, on online platforms and the affordances of these platforms for communicative interaction are exciting. Unfortunately, most platform-based language learning experiences are a relentless diet of drag-and-drop, drag-till-you-drop grammar or vocabulary gap-filling. The chat rooms and discussion forums that the platforms incorporate are underused or ignored. Lindsay Clandfield and Jill Hadfield’s new book is intended to promote online interaction between and among learners and the instructor, rather than between learners and software.